
xG: Arquitectura, Sesgos y Desarrollo
El análisis de datos en el fútbol ha vivido una transformación radical en la última década. Hemos pasado de contar eventos simples a construir modelos predictivos complejos que intentan descifrar patrones ocultos en el caos del juego. En el centro de esta revolución se encuentra el xG (Expected Goals o Goles Esperados), una métrica que ha cambiado por completo cómo clubes, analistas y aficionados entendemos el rendimiento ofensivo y defensivo. A diferencia de las estadísticas tradicionales que tratan todos los disparos igual, el xG asigna una probabilidad individual a cada intento de gol, permitiendo evaluar con matices la calidad real de las oportunidades creadas. Este análisis técnico desglosa la fundamentación matemática del xG, cómo se construyen estos modelos, las limitaciones críticas que cualquier analista debe conocer y las fronteras tecnológicas que a finales de 2025 integran inteligencia artificial y datos de seguimiento en tres dimensiones.
1. Ontología y Aplicación del xG en el Análisis de Rendimiento
El modelo de Goles Esperados es, en esencia, un estimador de probabilidad que cuantifica cuán peligrosa es una situación de disparo basándose en datos históricos de miles de eventos similares. Se expresa como un valor numérico entre 0 y 1, donde 0 representa una imposibilidad teórica de anotar y 1 una certeza absoluta. Por ejemplo, un disparo desde el área pequeña tras un centro raso puede recibir un valor de 0.65 xG, indicando que estadísticamente el 65% de disparos en esas condiciones terminan en gol.
1.1. Propósitos en el Ecosistema Profesional
El xG cumple múltiples funciones que van mucho más allá del simple reporte de resultados. Primero, actúa como un filtro contra la aleatoriedad. El fútbol es un deporte de baja anotación donde el azar juega un papel enorme en el resultado final; el xG permite identificar si un equipo está ganando porque tiene una estructura creativa superior o simplemente porque está viviendo una racha de buena fortuna.
En el mundo del reclutamiento y scouting, el xG permite detectar jugadores infravalorados. Un delantero que genera 0.80 xG por cada 90 minutos pero que solo ha anotado dos goles en diez partidos es, para un analista de datos, un activo valioso cuyo rendimiento goleador probablemente regresará a la media. Por el contrario, un jugador que anota diez goles con solo 3.0 xG acumulado puede estar operando bajo una "anomalía de varianza" insostenible a largo plazo.
2. Marco Matemático y Arquitecturas de Machine Learning
El funcionamiento técnico de un modelo de xG moderno se basa en el aprendizaje supervisado. El objetivo es entrenar un algoritmo que aprenda la relación entre las características de un disparo (variables independientes) y el resultado binario de gol o no-gol (variable dependiente).
2.1. Regresión Logística: La Base Estadística
Muchos de los modelos iniciales y algunos comerciales actuales utilizan la regresión logística como motor principal. Este modelo lineal es ideal para problemas de clasificación binaria porque utiliza la función sigmoide para mapear cualquier valor real al intervalo [0, 1]. La fórmula general de la probabilidad de gol se define como:
Donde son los pesos asignados a cada característica . La ventaja de la regresión logística está en su interpretabilidad; los analistas pueden entender exactamente cuánto influye un metro adicional de distancia en la caída de la probabilidad de gol.
2.2. Modelos Basados en Árboles: XGBoost y LightGBM
A medida que se incorporan variables más complejas, como la presión defensiva o la posición del portero, la linealidad de la regresión logística se convierte en una limitación. Los modelos actuales de vanguardia emplean algoritmos de Gradient Boosting, específicamente XGBoost (eXtreme Gradient Boosting) y LightGBM.
XGBoost utiliza un conjunto de árboles de decisión débiles entrenados secuencialmente para minimizar una función de pérdida (generalmente log-loss). A diferencia de los modelos lineales, los árboles pueden capturar interacciones no lineales complejas, como el hecho de que un cabezazo sea significativamente más difícil de anotar que un disparo con el pie a la misma distancia, o que la presión defensiva afecte de forma distinta a los disparos desde fuera del área que a los tiros cercanos.
2.3. Variables Principales del Modelo
La precisión de un modelo de xG depende críticamente de la calidad y profundidad de las variables integradas. Las variables se dividen generalmente en tres categorías:
Variables Espaciales: Incluyen la distancia euclidiana al centro de la portería y el ángulo de visión de la misma. El ángulo es especialmente relevante, ya que determina la superficie de la portería disponible para el rematador; se calcula comúnmente mediante la ley de los cosenos utilizando las coordenadas del punto de disparo y ambos postes.
Variables Técnicas: Indican si el disparo fue con la cabeza o el pie, si fue de volea, tras un regate al portero, o si fue un disparo de primera intención.
Variables de Contexto y Juego: Tipo de asistencia (centro, pase filtrado, rebote), patrón de juego (contraataque, jugada a balón parado, ataque posicional) y la presencia de defensores entre el balón y la portería.
3. Limitaciones, Sesgos y Desafíos Críticos
A pesar de su aceptación generalizada, el modelo de xG no es una representación perfecta de la realidad, sino una simplificación estadística. Para un analista profesional, comprender estas limitaciones es más importante que conocer el valor de xG en sí mismo.
3.1. El Sesgo del "Jugador Promedio"
La limitación más intrínseca del xG estándar es que asume que el ejecutor del disparo es un "jugador promedio". La mayoría de los modelos se entrenan con bases de datos masivas que diluyen las habilidades individuales. Esto genera dos problemas graves:
Subestimación de la Élite: Los mejores finalizadores del mundo, como Lionel Messi, Harry Kane o Erling Haaland, superan sistemáticamente su xG acumulado durante años. Pero el xG es "genérico" para todos los jugadores.
Sobreestimación de Jugadores de Nivel Bajo: Inversamente, un defensor que toma un disparo ocasional desde 20 metros recibe la misma probabilidad que un especialista en tiros lejanos, lo que infla artificialmente las expectativas sobre jugadores menos técnicos.
3.2. La Trampa de Monte Carlo y el Tamaño de la Muestra
El xG es una métrica de alta varianza a corto plazo. Debido a que el fútbol es un deporte de eventos discretos y escasos, la desviación entre los goles reales y los esperados (Goals Above Expectation o GAX) es muy ruidosa en muestras pequeñas. Un delantero puede tener una racha de cinco partidos sin marcar a pesar de acumular 4.5 xG; esto no siempre refleja una pérdida de forma, sino simplemente la naturaleza estocástica de la probabilidad. Los analistas sugieren que se requieren al menos 100-150 disparos para que la "señal" de la habilidad de finalización comience a emerger sobre el "ruido" de la varianza.
3.3. Interdependencia y Sucesión de Eventos
Un problema común en los agregados de xG de un partido es el tratamiento de los rebotes. Si un jugador dispara (0.60 xG), el portero para el balón y el mismo jugador remata el rebote (0.80 xG), la suma simple daría 1.40 xG para una sola jugada. Esto es lógicamente imposible, ya que no se pueden marcar más de 1.0 goles en una sola posesión. Los modelos avanzados intentan mitigar esto utilizando probabilidades condicionales o seleccionando solo el disparo con el valor de xG más alto en una cadena de posesión específica.
3.4. Calidad y Granularidad de los Datos (Providers)
No todos los modelos de xG son iguales porque no todos los datos de entrada tienen la misma calidad.
Opta vs. StatsBomb: Mientras que Opta se basa tradicionalmente en datos de eventos, StatsBomb incluye "Freeze Frames" que capturan la posición de todos los jugadores en el campo al momento del tiro. Esto permite a StatsBomb identificar si un disparo desde el área pequeña tiene una trayectoria bloqueada por tres defensores o si la portería está vacía, algo que un modelo basado solo en coordenadas (X, Y) ignoraría por completo.
Sesgo de Estado de Juego: Los equipos que van perdiendo tienden a realizar disparos más especulativos y de baja calidad al final del partido para intentar empatar. Estos disparos inflan el xG acumulado pero no necesariamente reflejan un mejor juego, un fenómeno que puede confundir la interpretación del dominio táctico.
4. Pipeline de Datos: Cómo se Construye un Modelo de xG
Para un analista de datos, la construcción de un modelo de xG sigue un flujo de trabajo de ciencia de datos estándar, pero con desafíos específicos del dominio futbolístico.
4.1. Extracción y Preprocesamiento
El pipeline comienza con la ingesta de archivos JSON o XML de proveedores de datos. Los pasos críticos incluyen:
Limpieza de Coordenadas: Las coordenadas deben normalizarse a un sistema estándar. Por ejemplo, en los datos de StatsBomb, las coordenadas X e Y van de 0 a 120 y 0 a 80 respectivamente.
Rotación de Campo: Es imperativo asegurar que todos los disparos se dirijan hacia la misma portería (generalmente la derecha en la visualización o el eje X máximo) para que las variables espaciales sean consistentes.
Filtrado de Eventos: Se deben eliminar los penaltis del entrenamiento del modelo general de juego abierto, ya que su probabilidad es constante (aproximadamente 0.78 xG) y su inclusión sesgaría los coeficientes de distancia y ángulo.
4.2. Ingeniería de Características (Feature Engineering)
Esta es la fase donde se genera el valor añadido mediante fórmulas físicas y trigonométricas:
Distancia Euclidiana: Cálculo directo usando el teorema de Pitágoras desde el punto de disparo al centro de la portería.
Ángulo de Tiro: Calculado mediante , donde es el ancho de la portería (7.32m) y la distancia.
Variables Categóricas: Transformación del tipo de asistencia o parte del cuerpo en variables "dummy" o codificación de factores.
4.3. Entrenamiento y Evaluación del Modelo
Debido a que los goles son eventos raros (aproximadamente el 10% de los disparos terminan en gol), el conjunto de datos está muy desequilibrado.
Manejo del Desequilibrio: Se pueden usar técnicas como el sobremuestreo (SMOTE) o el ajuste de pesos en la función de pérdida para que el modelo no aprenda simplemente a predecir "no gol" en todos los casos.
Evaluación Técnica: Más allá de la precisión, se utilizan:
- Log-Loss: Mide la incertidumbre de las probabilidades.
- Brier Score: Mide la exactitud de las predicciones probabilísticas.
- Área bajo la curva ROC (AUC): Evalúa la capacidad de discriminación entre gol y no-gol.
5. Información Relevante: El Futuro del xG en 2025
El interés por el xG ha derivado en la creación de métricas más profundas que complementan la visión del analista.
5.1. xGOT: El Valor Post-Disparo
El Expected Goals on Target (xGOT) o Post-Shot xG mide la probabilidad de gol una vez que el balón ya ha salido del pie y se conoce su trayectoria.
Implicación: Mientras que el xG nos dice qué tan buena era la oportunidad, el xGOT nos dice qué tan bueno fue el disparo. Un disparo con 0.10 xG que termina en la escuadra puede subir a 0.85 xGOT. La diferencia entre xGOT y xG se denomina "Shooting Goals Added" y es el mejor indicador de la calidad técnica de un rematador. Es especialmente relevante para evaluar porteros.
5.2. Métricas de Posesión: xG Chain y xG Build-up
Desarrolladas para dar crédito a jugadores que no asisten ni marcan, como los pivotes organizadores o los centrales con buena salida de balón.
xG Chain: Atribuye el xG de un disparo final a todos los jugadores involucrados en la cadena de pases previa.
xG Build-up: Igual que el xG Chain, pero excluye al que da la asistencia y al que remata, resaltando el valor de la construcción de juego pura.
5.3. Skor-xG y el Análisis de Esqueletos 3D
La innovación más reciente a finales de 2025 es la integración de datos de seguimiento de extremidades (Skeletal Tracking). Modelos como Skor-xG utilizan 3D Skeleton tracking para identificar la postura exacta del jugador al momento del remate.
Avance Tecnológico: Estos modelos procesan 21 articulaciones corporales y utilizan redes neuronales de grafos (GATv2). Esto permite saber si un jugador está rematando de espaldas, si su pierna de apoyo está bien colocada o si el portero tiene los brazos extendidos. Los resultados muestran que Skor-xG reduce significativamente el error de calibración (ECE) frente a los modelos tradicionales basados solo en eventos.
5.4. Bayes-xG: Personalización del Modelo
Para resolver el problema del "jugador promedio", los modelos Bayesianos Jerárquicos están ganando terreno en los clubes de élite. Estos modelos permiten que el xG se ajuste automáticamente según el histórico del jugador rematador.
Mecanismo: El modelo aprende un "efecto aleatorio" para cada jugador. Si el modelo observa que un jugador anota sistemáticamente disparos difíciles, el Bayes-xG ajusta la probabilidad hacia arriba para ese individuo específico, permitiendo un scouting mucho más preciso de la habilidad de finalización pura.
6. Caso Práctico: Desarrollo de un Modelo xG con XGBoost
Para ilustrar el proceso completo de construcción de un modelo de xG moderno, se ha implementado un sistema iterativo utilizando XGBoost y StatsBomb Open Data. Este caso práctico permite comprender las decisiones técnicas, las mejoras incrementales y las limitaciones reales que enfrenta un analista al construir un modelo de producción.
6.1. Decisión Arquitectónica: Por Qué XGBoost
Existen múltiples algoritmos capaces de resolver el problema de clasificación binaria que representa el xG. La decisión de utilizar XGBoost se fundamenta en tres factores críticos para datos tabulares de eventos futbolísticos:
Manejo de No Linealidades Complejas: A diferencia de la regresión logística, XGBoost puede capturar interacciones entre variables sin especificarlas manualmente. Por ejemplo, el impacto de la distancia al arco varía radicalmente según si el disparo es con la cabeza o con el pie, una relación que un modelo lineal no puede aprender automáticamente.
Eficiencia Computacional: Con un dataset de 88,000 disparos, XGBoost entrena en aproximadamente 3 minutos en hardware estándar, permitiendo iteración rápida. Las redes neuronales profundas requerirían horas de entrenamiento sin garantía de mejora para datos tabulares.
Monotonicity Constraints Nativos: XGBoost permite especificar restricciones monotónicas en las variables. Es fundamental que el modelo respete que a mayor distancia, menor probabilidad de gol, evitando aprendizaje de correlaciones espurias. Esta capacidad es crítica para generar predicciones realistas y consistentes con la física del juego.
XGBoost opera construyendo un conjunto de árboles de decisión débiles que se entrenan secuencialmente para minimizar la pérdida logarítmica. Cada árbol corrige los errores de los anteriores, generando un modelo robusto que domina en competencias de machine learning para datos tabulares.
6.2. Dataset: StatsBomb Open Data
El modelo se construyó utilizando StatsBomb Open Data, una de las fuentes públicas de mayor calidad en análisis futbolístico. El dataset final incluye:
- Total de Disparos: 88,023 shots de juego abierto
- Competiciones: La Liga (2018-2021), Premier League (2015/16), Champions League (2015-2019), Copa del Mundo 2022
- Temporalidad: 23 temporadas desde 2003 hasta 2024
- Tasa de Conversión: 10.2% (8,791 goles)
El preprocesamiento incluye la eliminación de penaltis (probabilidad constante de 0.78), disparos hacia la portería incorrecta (X < 60 en coordenadas StatsBomb) y eventos con coordenadas inválidas. Esta limpieza reduce el ruido y permite que el modelo aprenda patrones genuinos de xG en juego abierto.
La ventaja clave de StatsBomb es la inclusión de Freeze Frames: capturas de la posición exacta de todos los jugadores en el momento del disparo. Esto permite modelar presión defensiva y obstrucción de trayectorias, variables que sistemas basados solo en coordenadas (X, Y) ignoran completamente.
6.3. Desarrollo Iterativo en Cinco Fases
El enfoque de desarrollo fue incremental, añadiendo complejidad progresivamente para identificar qué variables aportan valor real. Este proceso permite cuantificar el impacto de cada categoría de features.
Phase 1: Baseline Geométrico (Brier: 0.085)
- Variables: distance_to_goal, angle_to_goal, x_coordinate, y_deviation, body_part, technique, shot_type
- Monotonicity: Distancia negativa, ángulo positivo
- Resultado: Este modelo básico ya supera estimaciones triviales, pero ignora completamente el contexto defensivo.
Phase 2 Tuned: Freeze Frames + Hyperparameter Optimization (Brier: 0.0755) - Pure xG
- Variables añadidas: keeper_distance_from_line, keeper_lateral_deviation, keeper_cone_blocked, defenders_in_triangle, closest_defender_distance, defenders_within_5m, defenders_in_shooting_lane
- Optimización: RandomizedSearchCV con 50 iteraciones y 5-fold CV para encontrar hiperparámetros óptimos
- Hiperparámetros finales: max_depth=4, learning_rate=0.05, n_estimators=400, subsample=0.8, colsample_bytree=0.8, reg_alpha=0.3, reg_lambda=3.0, min_child_weight=5
- Métricas de validación: Test Brier=0.0755, AUC=0.8132, sin evidencia de overfitting (diff +0.0026)
- Impacto: Este modelo representa el xG puro (pre-shot) óptimo, utilizando exclusivamente features disponibles al momento del disparo
- Recomendación: Phase 2 Tuned es el modelo recomendado para comparaciones justas con modelos comerciales de xG, ya que no incluye información post-shot. Las variables de presión defensiva capturan el 80% del valor añadido del modelo. Un disparo desde el área pequeña con tres defensores bloqueando la trayectoria tiene un xG dramáticamente distinto al mismo disparo con portería vacía.
Phase 3: Shot Height (Brier: 0.0648) - Post-Shot xG
- Variables añadidas: shot_height (coordenada Z de end_location), is_header_aerial_won, keeper_forward_high_shot
- Impacto: Reducción de 0.0072 en Brier Score
- Resultado Final: Brier Score de 0.0648 supera el target establecido (0.068) y el modelo comercial de StatsBomb (0.0745), representando una mejora del 13%.
NOTA CRÍTICA: Phase 3 incorpora shot_height extraído de end_location[2], que representa dónde terminó el balón (altura en portería, manos del portero, fuera del arco). Esta es información POST-SHOT, no disponible al momento del disparo. Por tanto, Phase 3 es técnicamente un modelo de Post-Shot xG (xGOT) que mide tanto la calidad de la oportunidad (pre-shot) como la calidad de la ejecución (post-shot). Para comparaciones justas con modelos comerciales de xG puro (como StatsBomb), se debe utilizar Phase 2, que emplea exclusivamente variables pre-shot conocidas al momento del remate.
La altura del disparo resulta ser la feature individual más importante del modelo (gain: 101.8), superando incluso a la distancia y el ángulo. Los cabezazos, por ejemplo, tienen una probabilidad inherentemente menor que disparos con el pie a la misma distancia, una distinción que modelos simples no capturan adecuadamente.
Phase 4: Contextual Features (Brier: 0.0649)
- Variables añadidas: first_time (disparo de primera), under_pressure (jugador presionado), one_on_one (mano a mano con el portero)
- Resultado: NO hay mejora significativa
- Interpretación Crítica: Las features contextuales aportan información redundante. La combinación de geometría y freeze frames ya captura indirectamente el contexto táctico. Un disparo one_on_one, por ejemplo, ya se refleja en la posición adelantada del portero y la ausencia de defensores en el triángulo.
Phase 5: 360 Data (En desarrollo)
- Variables planificadas: visible_area_size, goal_visibility_score, pressure_density_360
- Limitación: Solo aproximadamente el 10% de los disparos tienen datos 360 completos
- Enfoque: Transfer learning desde Phase 3, fine-tuning con learning rate bajo
6.4. Comparación vs StatsBomb: Análisis de Discrepancias
Para una comparación justa con el modelo comercial de StatsBomb, se utiliza Phase 2 Tuned (pure xG) que emplea exclusivamente features pre-shot. Aunque Phase 3 obtiene mejor Brier Score (0.0648), incluye información post-shot y representa técnicamente un modelo de xGOT.
Métricas Globales (Phase 2 Tuned vs StatsBomb):
- Brier Score: 0.0755 vs 0.0745 (comparable, diferencia no significativa)
- AUC-ROC: 0.8132 (capacidad de discriminación robusta)
- Correlación: 0.932 (muy alto)
- Mean Absolute Error: 0.027 (diferencia promedio de 2.7 puntos porcentuales de xG)
El modelo Phase 2 Tuned alcanza métricas comparables al modelo comercial de StatsBomb utilizando exclusivamente datos públicos y features pre-shot, validando la arquitectura y el enfoque de ingeniería de características empleado.
Patrones de Discrepancia (Phase 2 Tuned vs StatsBomb):
La alta correlación (0.932) indica que ambos modelos capturan patrones similares en la mayoría de escenarios. Las discrepancias se observan principalmente en:
Situaciones de Alta Presión Defensiva: Phase 2 Tuned, con sus features detalladas de freeze frame (defenders_in_shooting_lane, defenders_in_triangle), tiende a penalizar más agresivamente disparos con trayectorias obstruidas.
Geometría Extrema: En ángulos muy cerrados o distancias muy largas, las diferencias se amplían ligeramente debido a distintas arquitecturas de modelado (XGBoost con monotonicity constraints vs modelo propietario de StatsBomb).
Convergencia en Escenarios Claros: Ambos modelos convergen en situaciones de one-on-one y tiros desde el punto de penalti, validando la robustez de las features geométricas básicas compartidas.
Comparación Visual de modelos: Shot Maps Euro 2024 Final
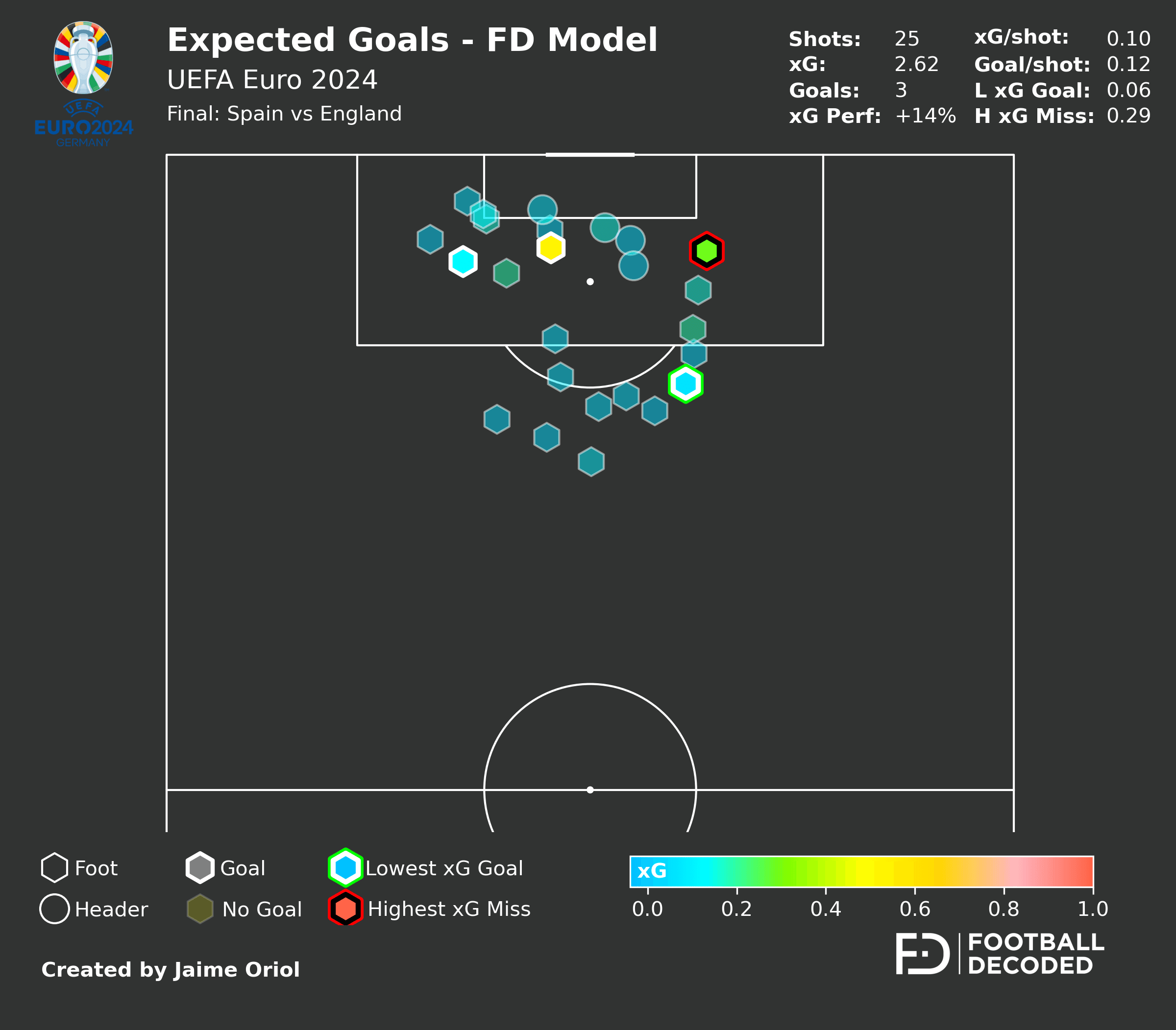

Un ejemplo práctico de las diferencias entre mi modelo (Phase 2 Tuned) y el modelo comercial de StatsBomb se puede observar en el shot map de la final de la Eurocopa 2024 entre España e Inglaterra. El primer mapa muestra las probabilidades generadas por mi modelo, mientras que el segundo corresponde a StatsBomb. Aunque ambos capturan los patrones generales de peligrosidad, se observan diferencias sutiles en la valoración de disparos desde posiciones similares, reflejando las distintas arquitecturas y features empleadas por cada sistema.
6.5. Calibración del Modelo
La calibración mide si las probabilidades predichas corresponden a las tasas observadas. Un modelo puede tener buen Brier Score pero estar mal calibrado si, por ejemplo, predice sistemáticamente 0.30 xG para disparos que tienen una tasa real de conversión del 50%.
El modelo Phase 2 Tuned, con un Brier Score de 0.0755 en el test set, demuestra predicciones probabilísticas precisas. El bajo Brier Score es un indicador directo de buena calibración, ya que penaliza tanto la falta de discriminación como la mala calibración.
Los hiperparámetros optimizados (particularmente la regularización con reg_lambda=3.0 y reg_alpha=0.3) ayudan a prevenir overconfidence en las predicciones, un problema común en modelos sin regularización adecuada. Las monotonicity constraints aseguran que las probabilidades sigan patrones físicamente realistas, contribuyendo a una calibración robusta en escenarios extremos de geometría.
6.6. Limitaciones y Perspectivas Futuras
A pesar de alcanzar métricas comparables a modelos comerciales utilizando exclusivamente datos públicos, Phase 2 Tuned comparte las limitaciones fundamentales de todos los sistemas de xG basados en el "jugador promedio":
Homogeneización de Habilidad: El modelo no distingue entre un remate de Lionel Messi y uno de un defensor central. Un sistema Bayesiano Jerárquico permitiría ajustar las probabilidades según el histórico individual del rematador.
Ausencia de Trayectoria Post-Disparo: El modelo evalúa la calidad de la oportunidad, no del disparo ejecutado. Un Post-Shot xG (xGOT) requeriría datos de tracking de balón para medir la probabilidad de gol después de conocer la trayectoria real.
Cobertura Limitada de Datos 360: Solo el 10% del dataset incluye información completa de visibilidad y esqueletos 3D, limitando el potencial de Phase 5.
Conclusiones
El modelo de Expected Goals ha madurado de ser una estadística avanzada a convertirse en un lenguaje fundamental para la toma de decisiones en el fútbol profesional. Sin embargo, la sofisticación técnica debe ir acompañada de una interpretación cautelosa. El xG es más potente cuando se agrega en muestras grandes y cuando se utiliza para evaluar procesos, no resultados aislados.
Para el analista moderno, el camino a seguir implica la integración de múltiples fuentes: datos de eventos para el contexto, tracking 3D para la física del movimiento y modelos jerárquicos para la personalización del talento. En última instancia, el xG no pretende predecir el futuro con certeza absoluta, sino proporcionar una base científica para gestionar la incertidumbre y maximizar las probabilidades de éxito en el deporte más impredecible del mundo.
Todo el código, notebooks y análisis completo del desarrollo están disponibles en mi GitHub: github.com/jaime-oriol/xG_Model con el pipeline completo, las 5 fases de desarrollo, scripts de evaluación vs StatsBomb y notebooks reproducibles para entrenar tu propio modelo.
¿Crees que los modelos basados en "jugador promedio" serán reemplazados por sistemas Bayesianos personalizados? ¿Qué otras variables consideras críticas para mejorar la precisión del xG? ¿Cómo equilibras métricas avanzadas con el análisis cualitativo del juego?
Artículo anterior
Messi a los 38: La Temporada que Redefine lo Imposible
Siguiente artículo
